-
随波逐流OCR识别工具软件
- 大小:345.22 M
- 语言:简体中文
- 类别: 系统辅助
- 系统:Win






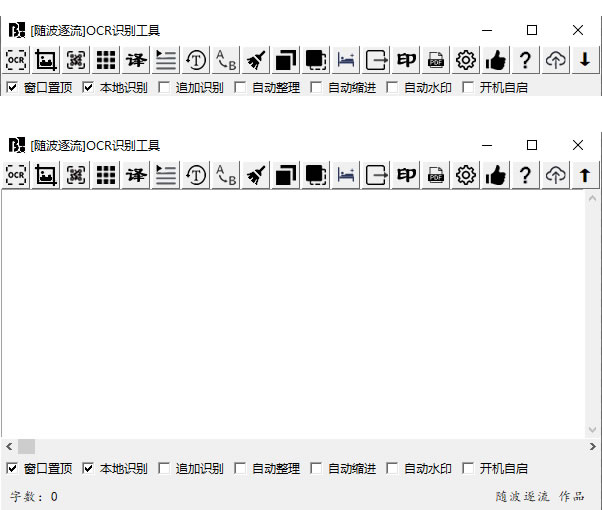
随波逐流OCR识别工具是一款基于Windows系统的,集图像导入、截取、识别、翻译、搜索、导出于一体的文字、PDF文件、条码、表格、公式识别软件。OCR文字识别方便快捷,能够满足用户在各种场景下的文字识别需求,为用户提供了便捷、高效的文字识别解决方案。可以通过使用随波逐流OCR文字识别工具来提升工作效率,节省时间成本,实现数字化文档管理和信息处理。
随波逐流OCR识别工具软件亮点
离线识别优势
本地模型调用不受网络限制,且对PDF多页识别无页数限制(百度接口按页计费)。
在线识别补充
百度OCR接口提供更高精度的识别服务,但需联网且可能受调用次数限制。
兼容性与依赖
基于Windows 64位系统开发,需安装 Visual C++ Redistributable Packages for Visual Studio 2013 依赖库(部分电脑报错原因)。
随波逐流OCR识别工具软件特色
办公场景
快速提取合同、报告中的文字内容,转换为可编辑格式。
识别发票、名片等票据信息,自动分类整理。
学习场景
截图识别教材、课件中的文字,支持翻译和笔记整理。
将扫描的论文或书籍转换为Word文档,便于标注和引用。
生活场景
识别商品条码查询价格或信息。
上传图片至图床,生成分享链接。
随波逐流OCR识别工具软件功能
OCR文字识别
本地离线识别:调用本地模型进行文字识别,无需依赖网络环境,适合内网或无网络场景使用。
在线识别(可选):保留百度OCR在线接口(需联网),支持更高精度的识别需求。
多语言支持:在线翻译功能支持数十种语言互译,满足国际化需求。
屏幕截图与编辑
快捷截图:默认快捷键 F7 或 F9(不同版本可能不同),支持类360截图的编辑功能,可添加图片说明或标注。
区域截图:鼠标划定屏幕区域进行精准截图,适用于局部文字识别或信息提取。
条码与二维码识别
支持多种条码类型,包括 1D Product/Industrial、2D UPC-A、QR Code、EAN-8/13、Code 39/128 等,无需联网即可解码。
表格识别
可识别图片或PDF中的表格结构,支持导出为 Excel(.xlsx) 或 CSV 格式,保留原始排版。
PDF文件处理
PDF转DOCX:将扫描型PDF转换为可编辑的Word文档。
双层PDF输出:识别后生成可搜索的文本层,同时保留原始图像层(需结合离线识别功能)。
智能整理与导出
支持对识别结果进行整理、复制、导出为TXT或图片文件,提升文档管理效率。
图床上传与图片加水印
识别后的图片可快速上传至图床,或添加水印保护版权。
随波逐流OCR识别工具软件使用方法
使用方法:
例:文本OCR识别
例:屏幕截图
“截图”增加编辑功能,方便增加图片说明
截图默认快捷键F7
例:条码识别

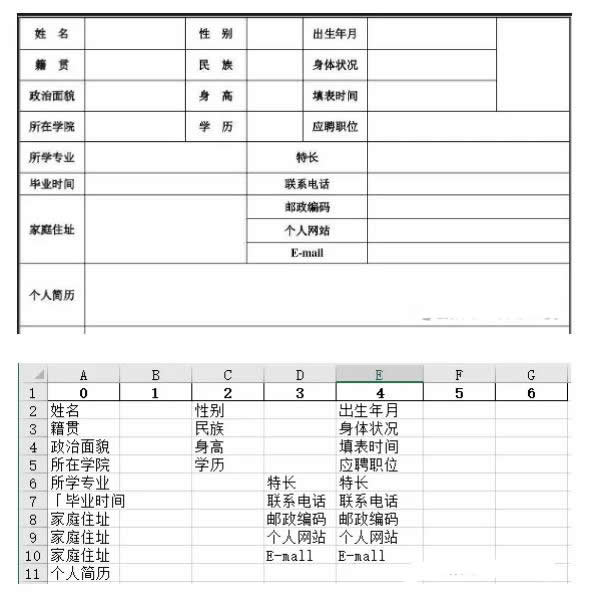
例:在线翻译(支持多达几十种语言翻译)
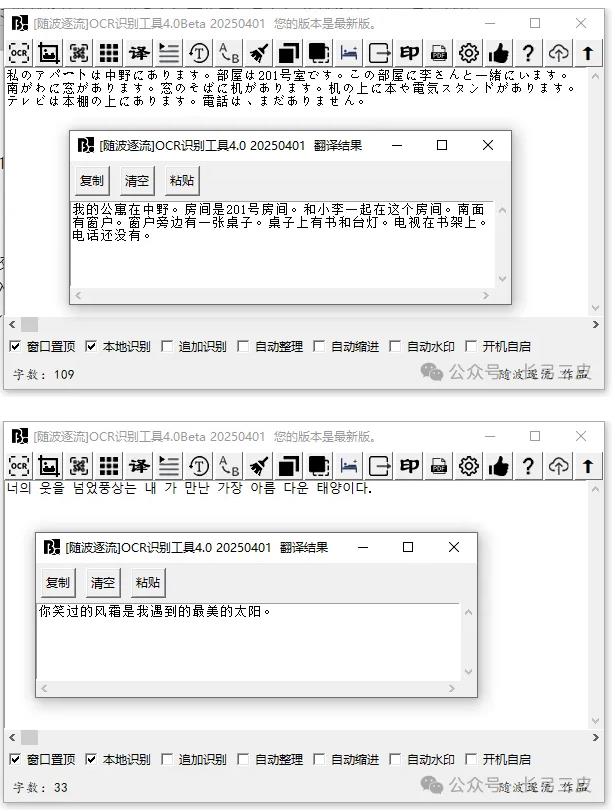
例:上传图床
例:图片加水印
例:PDF转DOCX
随波逐流OCR识别工具软件常见问题
图像质量问题导致的识别错误
问题描述:图像模糊、有噪声或倾斜变形,导致文字难以识别。
解决方案:
提升图像质量:确保拍摄环境光线充足,使用高像素设备拍摄,并保持稳定拍摄。
图像预处理:使用图像处理软件对图片进行灰度化、二值化、降噪等操作,提升图像质量。例如,使用锐化技术提高图像清晰度,或使用中值滤波、高斯滤波去除噪声。
图像矫正:对于倾斜或变形的图像,使用透视变换或仿射变换技术进行矫正。
随波逐流OCR识别工具软件更新日志:
1.修复部分bug
2.优化了部分功能
华军小编推荐:
随波逐流OCR识别工具软件一直以来是大多数小伙伴常用系统辅助软件,在网民心目中的可是有这霸主地位可见一般,华军软件园小编同学推荐广大用户下载随波逐流OCR识别工具软件使用,快来下载吧,另外还有批量小管家、.NET、云机管家提供下载。
版本: v1.25 | 更新时间: 2026-03-05