小编说:你这顾虑不无道理,虽然目前几大AI还是比较靠谱的,但是谁知道呢!
他说那咋办?我说那你本地部署大模型,用你自己的电脑跑AI,无需联网,不用担心泄密问题。安装使用也比较的简单,一学就会。
一拍即合,说干就干!接下来就跟着小编从零开始安装使用Ollama,在自己的电脑里部署AI大模型。保姆级教程,看完自己就能搞定!
Ollama这玩意到底是个啥
Ollama,简单的来说就是能把 AI 大模型装到你电脑上跑的工具。记住他只是一个壳子,在里面你可以安装各种的大模型,比如国产轻量化的通义千问 Qwen 系列、谷歌 Gemma 系列、Llama3 开源通用大模型、DeepSeek 深度求索开源大模型,还有专攻数学、翻译、文案创作的各类细分专用模型,全部都能下载到本地离线运行。
它不是网页版,不是云服务。模型下完存你本地硬盘,运行全靠你电脑的CPU和显卡。你问它什么,它在你电脑里算完给你回答,没有一个字发到外网。安全性不错。而且免费,不用算Token。
它是个全能的《十万个为什么》,相当于在电脑里装了个百科全书甚至于说是一个图书馆,博古通今,知识渊博。
你的电脑能不能用Ollama
我们先来看看你的电脑能不能用,先搞懂几个问题。用自己的电脑跑大模型涉及两个东西,很多人搞混。小编先给你捋清楚。
系统内存(RAM):就是配置单上写的8G、16G、32G,平常开微信开浏览器用的那个。跑大模型的时候,模型得加载到内存里才能算。没显卡的电脑,模型全靠系统内存跑。总体推荐8G以上。
显卡显存(VRAM):显卡自带的专属内存,跟系统内存不是一回事。N卡一般4G到24G(RTX 3060是12G显存)。显存算得比系统内存快得多。
显卡要求:要求: GPU:RTX 3060 或同等性能显卡(8GB显存以上) ,支持纯 CPU 无独显运行轻量模型,8G 内存笔记本不带显卡也能跑 qwen3.5:2b。
那具体能跑多大模型呢?看系统内存:
8G内存,跑qwen3.5:2b或gemma4:e2b,聊天写短文够用,速度一般。再大的模型能加载但内存会被吃满,开别的软件会卡。
16G内存,跑gemma4:4b或qwen3.5:4b。这是2026年最新的模型,逻辑强长文流畅还支持识图。gemma4是谷歌刚更新的,回答质量很稳。大多数人选这个。最适合配置一般偏上的电脑。
32G内存+5060显卡,gemma4:12b、qwen3.5:9b随便上,写论文写代码不虚。
Ollama安装使用保姆级教程
1.1 Ollama的安装
Ollama下载安装,跟安装普通软件的方式差不多,下载安装包,然后下一步下一步就能安装完毕。
首先用浏览器打开 https://ollama.com/download。网站自动识别Windows,页面上一个大按钮Download for Windows,点它下.exe安装包。最好别去第三方网盘下,不知道会不会下到加料版 。
下完双击打开,弹出安装窗口点Install,等进度条走完点Finish。不用你修改任何选项,傻瓜式安装操作,下一步策略就能安装完毕。整个安装过程比较的快,稍等片刻即可安装完毕。
安装完毕有两个标志:一是右下角任务栏出现一只小羊驼图标,后台服务启动了;还有就是主窗口自动弹出来。
装好之后常驻后台开机自启,跟微信一样,关了窗口图标还在,双击随时召唤。
1.2 为Ollama安装上大模型
别急着跟Ollama聊天,现在它还只是一个框架,你还得为它加上大脑,不然它怎么也不会理你的。
桌面客户端下模型的方式其实特别简单,但跟你想的不太一样--不是在客户端里搜,是先去网页上找。
● 第一步,浏览器打开 https://ollama.com/search
这是Ollama官方模型库,所有模型都在这,国内可访问。
●第二步,搜索框里输模型名
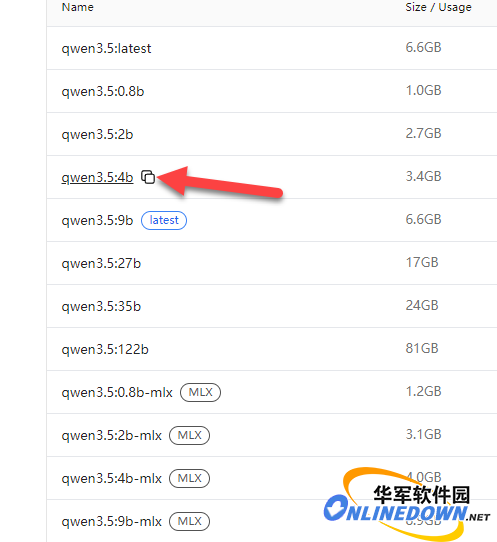
比如你想用通义千问,就搜 qwen。搜出来一堆结果,找到你要的那个版本,比如 qwen3.5,点进去。
●第三步,进模型详情页,找你电脑能跑的规格。
页面会列出这个模型所有可选的参数量版本,每个后面标了大小。根据你的内存选:
8G内存选 qwen3.5:4b,4B参数,约2.5GB,下得快启动快,日常够用。回答质量比老款qwen2.5强不少,电脑配置不高的可以先选它试试。
16G内存选 gemma4:4b,谷歌2026最新模型,逻辑强回答稳还支持识图。也可以同时下个qwen3.5:4b换着用,体积差不多。两个模型各有各的好,gemma4写东西更稳,qwen3.5中文理解更到位,看你自己习惯。
32G内存选 gemma4:12b 或 qwen3.5:9b,写论文写代码不虚。
插个话:各种级别的大模型能干什么
 3B/4B 轻量小模型(8G 内存低配电脑)
3B/4B 轻量小模型(8G 内存低配电脑)主打:聊天、写短句、翻译、简单作业、日常文案,速度快,复杂逻辑偏弱。
7B 通用主流模型(16G 内存首选,如 Qwen2.5、Gemma4)上面全部功能全覆盖,解题、写长文、简单代码、识图都流畅,性价比最高。
代码专用模型(DeepSeek-Coder、CodeLlama)写代码、排 BUG 能力拉满,日常聊天能力一般。
超大 13B/34B 模型(32G 内存高配)超强逻辑推理、长篇论文、复杂数学、深度商业分析,思考更全面精准。
●第四步,复制模型名
页面上每个规格旁边有个复制按钮,点一下就把模型名复制了,比如 `qwen3.5:4b`。手动选中复制也行。
●第五步,修改下边的命令
把你复制的模型名替换这个命令中的XXX "ollama run XXX",比如 "ollama run gemma4:e4b",复制一下这条命令。
●第六步:回到Windows,在开始菜单Windows图标处使用右键菜单,然后选择"终端管理员",在终端管理窗口中把刚刚复制的命令粘贴到这里,接着按下回车。
稍等片刻,就开始下载你所指定的大模型了。下载速度前边飞快,后边慢得像蜗牛,小编也不知道为何,只能等呗!安装完毕后重启ollama,就能在对话界面里的模型选择中找到你刚刚下载好的大模型了,开始对话吧。
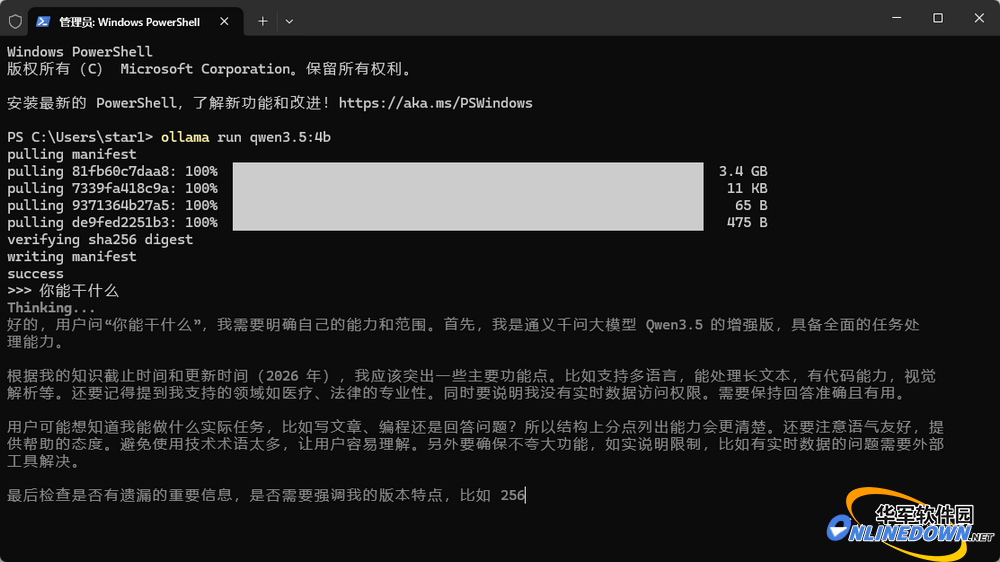 图6 把大模型下载回本地
图6 把大模型下载回本地
提醒一下,如果不想你的C盘爆满,可以在ollama的settings页面中的Model location把模型存放地址修改到别的盘。设置后再下载模型。
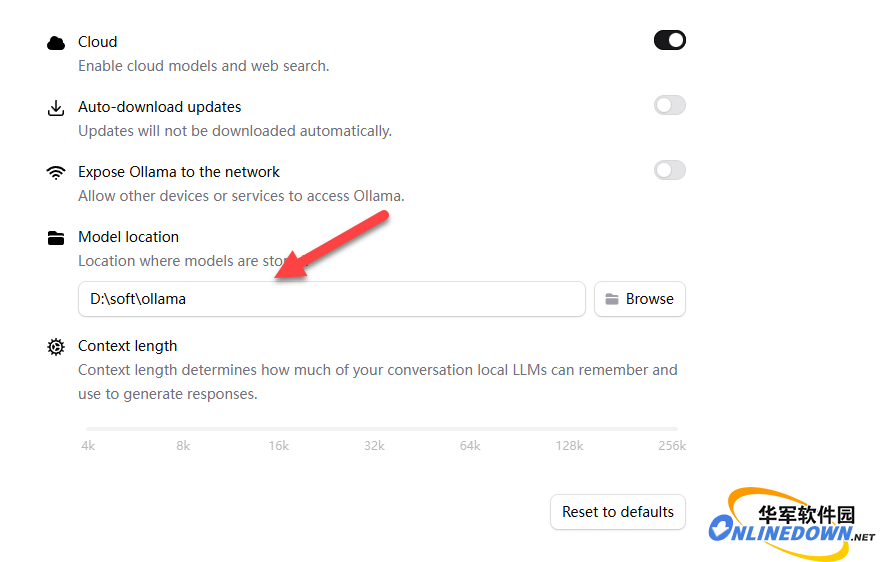 图7 设置模型存放路径
图7 设置模型存放路径
顺带提一嘴,Ollama还支持"越狱版"模型,就是经过特殊处理、解除了安全限制的那种。正规大模型碰到某些敏感问题会甩你一句"我无法回答",越狱版不会。具体怎么装、装哪个,小编这里不细说,懂的都懂,不懂的自己去搜。
1.3 Ollama的使用
跟旧版的Ollama不同,新版的Ollama已经有了专门的图形使用界面,大幅降低了使用门槛。打开Ollama,就能看到聊天对话界面,右下角有模型选择,选择一个下载好的模型(有云朵标志的为在线模型)。
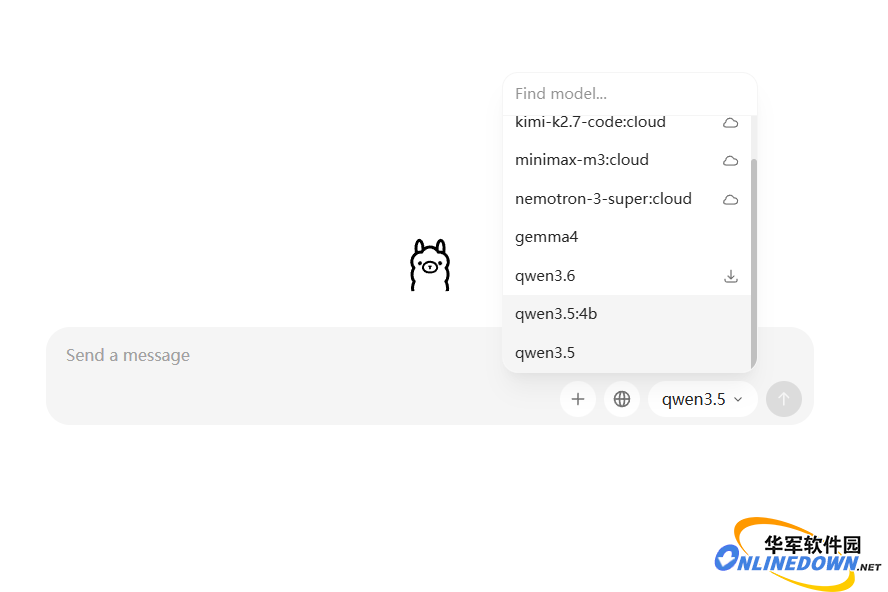 图8 选择下载好的大模型
图8 选择下载好的大模型
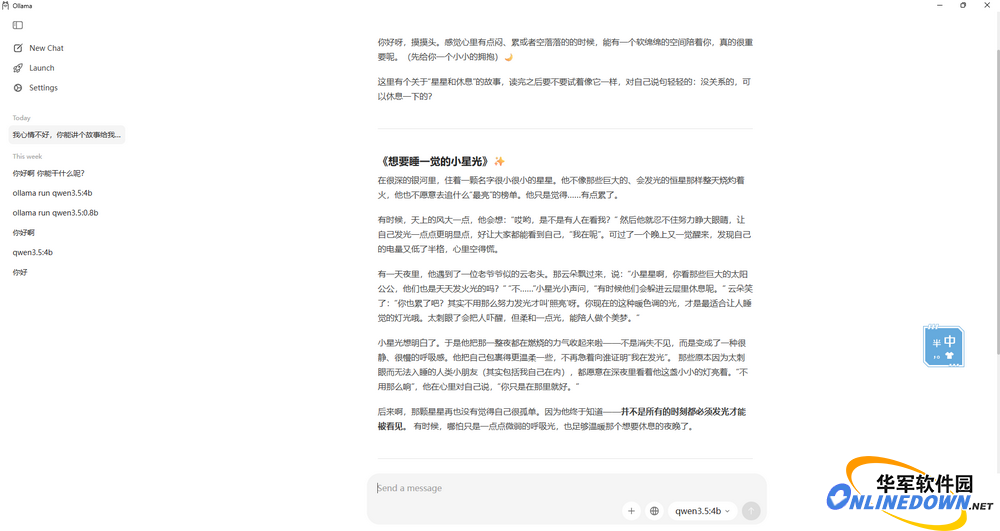
在对话框中输入你的问题,然后就等AI大模型的回答,回答速度跟你的电脑配置以及选择的大模型有关。有些大模型只支持文字,有的大模型支持图片识别。

图9 让AI识别图片内容
左侧New Chat开新对话,工作私事分开不串。底部下拉框随时切模型,聊天用轻量的大模型,回复速度快,写方案用高级别点的。不用的模型可以删掉腾出磁盘空间。
其它还需设置的地方:在Ollama的settings页面中的Context length选项中可以设置上下文长度,,决定模型在生成回复时能 "记住" 并参考的对话历史、输入文本总量,单位为 token。值越大,能容纳越长的对话 / 文档内容,但会占用更多显存 / 内存,推理速度变慢;值过小,长对话会被截断,模型容易 "忘前文"、回答前后矛盾。
恭喜你!如果你读到了这里并照着操作的话,说明你已经学会了本地大模型的部署和使用。从最初对数据泄密的顾虑,到如今能地在本地运行模型,你已经从一个AI的"使用者",蜕变为了一个AI的"掌控者"。
总结
本地跑AI,最大的价值在于安全、私有、可控,安装完毕后部署了大模型,你完全可以离线使用。你还可以安装多个不同的模型,把它当成一个"工具箱",利用各种模型各自擅长的领域:今天用A模型做代码,明天用B模型写报告,后天再用C模型做数据分析。多尝试,你会发现每个模型都有独特的"超能力"。